Building a Production-Grade URL Shortener SRE Lab: High Availability on a Homelab
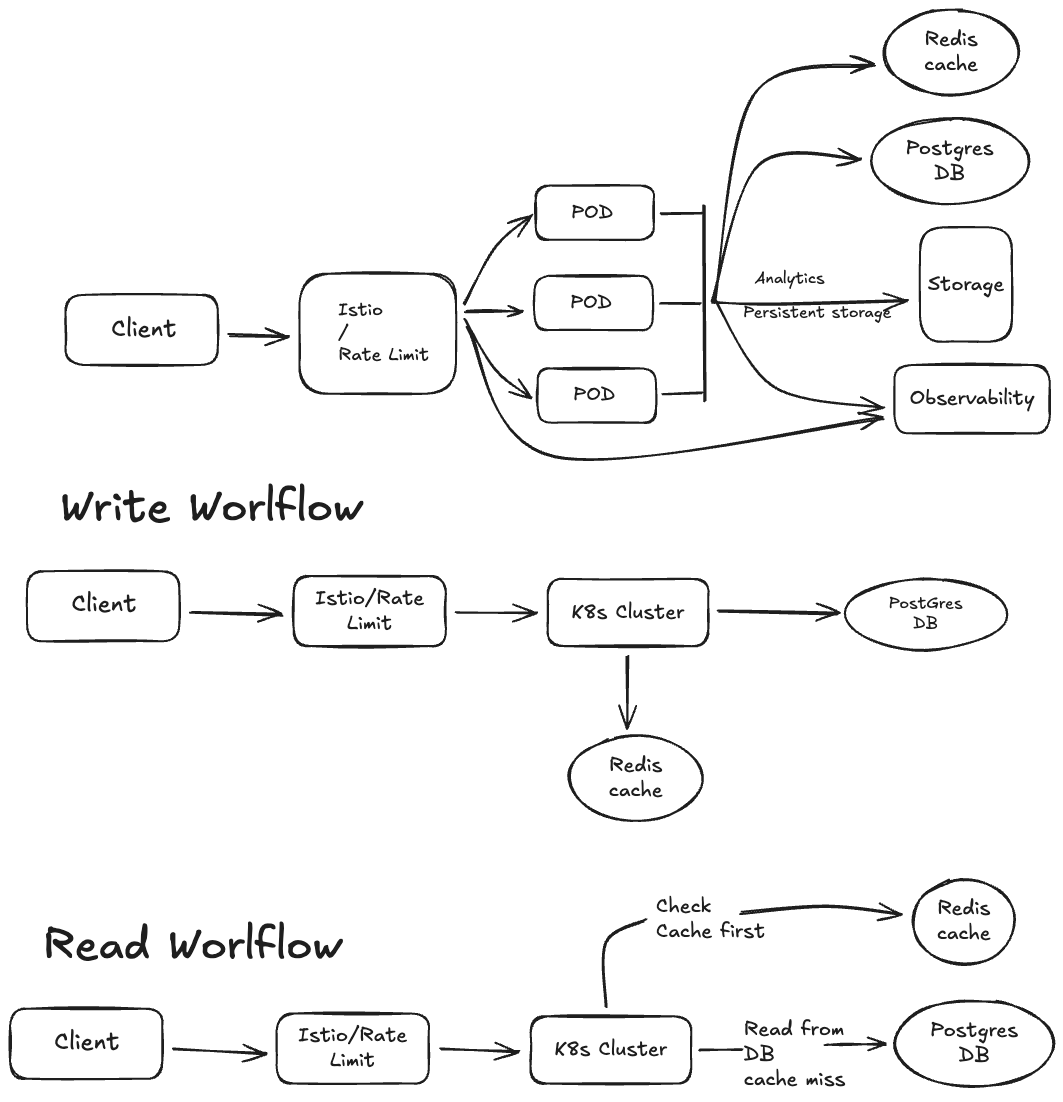
In the world of Site Reliability Engineering (SRE), theory is good, but practice is paramount. I’m currently in Phase 6 of a project designed to demonstrate modern SRE practices, infrastructure as code, and operational excellence: a Production-Grade URL Shortener deployed on a Kubernetes cluster.
While this system runs on a single Minisforum UM790 Pro mini PC in my homelab, it is architected to mimic a full-scale enterprise environment. By leveraging Proxmox VE for virtualization, I created a 3-node K3s High Availability (HA) cluster that hosts a complete observability stack, service mesh, and distributed database system.
Here is a look under the hood of the URL Shortener SRE Lab.
The Architecture: Why “Production-Grade”?
The goal wasn’t just to shorten URLs; it was to build a system resilient enough for a “viral event” while maintaining full visibility into every request. The architecture includes:
- Kubernetes Platform: A 3-node K3s HA cluster with embedded etcd. K3s was chosen for its low resource overhead (512MB RAM for the control plane vs. 2-3GB for standard Kubernetes), enabling true HA on a single physical host.
- Service Mesh: Istio v1.24.2. This provides “zero-code” observability, golden signal metrics, and distributed tracing without modifying the application code.
- GitOps Workflow: ArgoCD manages all deployments using an app-of-apps pattern. This ensures that the infrastructure is defined as code, allowing for automated syncs with pruning, self-healing, and easy rollbacks.
- Secrets Management: External Secrets Operator integrated with AWS Secrets Manager eliminates manual secret handling and provides an audit trail for credential access.
- Application Layer: Shlink v4.x running as 3 replicas for high availability.
Data Persistence and Caching
To ensure data integrity and speed, the system uses a split storage strategy:
- PostgreSQL (Source of Truth): Managed via the Crunchy Data Operator, providing ACID guarantees, automated backups, and a relational model for analytics.
- Redis (Performance Layer): A Redis Sentinel setup with 3 replicas and automatic failover. This layer is critical for handling high-traffic URLs, offloading read operations from the database.
The Caching Challenge and Solution
One of the most interesting technical hurdles encountered was a compatibility issue between the default Shlink image (which uses the Predis library) and Redis Sentinel. The Predis library doesn’t properly support Sentinel mode in Shlink’s Symfony cache configuration, resulting in errors like Cannot use object of type Predis\Response\Error as array.
To solve this, I built a custom Docker image (ghcr.io/manubalasree/shlink-phpredis:latest) that compiles the native phpredis C extension. The results were immediate and significant:
- Performance Gain: The system is now 76% faster with caching enabled.
- Cache Hit Rate: We achieved a 98.97% hit rate during testing.
- Latency: Cached responses are served in under 50ms, while uncached requests average around 100ms.
A PostgreSQL 15+ Gotcha
Another lesson learned: the Crunchy Data Operator creates database users but doesn’t automatically grant CREATE privileges on the public schema (a security change in PostgreSQL 15+). Migrations failed with permission denied for schema public until I manually ran:
GRANT ALL ON SCHEMA public TO shlink;
This is now documented for future deployments and will be automated via a Kubernetes Job.
Observability: Seeing the Unseen
A production system is only as good as your ability to monitor it. The SRE Lab integrates a comprehensive observability stack:
- Prometheus & Grafana: For collecting metrics and visualizing performance. Dashboards track P50, P95, and P99 latency percentiles.
- Jaeger: Configured for 100% sampling, Jaeger provides end-to-end distributed tracing, allowing us to see the exact flow of a request from the Istio Ingress Gateway to the application and down to the database.
- Kiali: Offers a real-time topology graph of the service mesh, visualizing traffic flow and health indicators.
The beauty of Istio’s sidecar injection is that all of this works without any application code changes—Envoy proxies automatically inject trace headers and collect metrics.
Performance Validation
We didn’t just assume the system was fast; we proved it using k6 load testing. The test scenarios were designed around realistic traffic modeling for 1000 Daily Active Users (DAU):
Traffic Analysis: 1000 DAU translates to ~5,000 URL creations and ~500,000 redirects daily (a 100:1 read:write ratio)
Three Progressive Scenarios:
- Scenario 1 (Baseline): Normal day traffic—1 creation/sec, 20 redirects/sec
- Scenario 2 (Peak Hours): Lunch/morning peaks—2 creations/sec, 50 redirects/sec
- Scenario 3 (Viral Event): Marketing campaign simulation—5-8 creations/sec, 100-200+ redirects/sec with Pareto distribution (80% traffic to 20% of URLs)
Under baseline load (Scenario 1), the system demonstrated:
- 100% Success Rate for both URL creation and redirects.
- URL Creation Latency: ~39ms median.
- Redirect Latency: ~28ms median.
Current Status and Roadmap
The project is approximately 92% complete with Phases 1-5 done and Phase 6.1 (load testing infrastructure) finished.
Remaining Work:
- Phase 6.2: Execute load tests and analyze performance results
- Phase 6.3: HA testing—node failures, pod disruptions, database and Redis failover scenarios
- Phase 7: Final documentation, operational runbooks, and demo preparation
Future Enhancements:
- Dynamic Redis master tracking: Currently, Shlink connects to a specific Redis pod. A future improvement will create a Kubernetes service that tracks the current master using the
redisfailovers-role=masterlabel selector for true HA failover support. - mTLS enablement: Strict mutual TLS between all services via Istio PeerAuthentication policies.
- Automated PostgreSQL permissions: A Kubernetes Job to handle schema grants post-deployment.
- Advanced alerting: Prometheus alerting rules for critical metrics with notification integration.
Conclusion
This lab serves as living documentation of how affordable hardware, combined with enterprise-grade open-source software like K3s, Istio, and ArgoCD, can create powerful, resilient systems.
For more details on the code, configuration, and documentation, view the repository at manubalasree/url-shortener-sre-lab.