The Bug Was Fixed at 2:25 AM. Full Recovery Took 28 Hours. Here’s Why
The Night the Scheduler Lied
Imagine a city-wide self-driving cab service. Every cab is electric. Every cab charges at one of hundreds of automated charging hubs scattered across the city. At the heart of each hub is a scheduling system — it knows which chargers are free, which are busy, and routes cabs accordingly.
One night, a software bug corrupts the scheduling system for 20 minutes. Not the chargers — just the scheduler. Cabs start getting told every charger is busy. They queue. They wait. The city’s cab availability collapses.
Engineers find the bug and fix it at 2:25 AM.
Then something unexpected happens. Every cab in the city — thousands of them — simultaneously rushes to the nearest charging hub to re-establish their slot. The hubs, which just recovered, are immediately overwhelmed. Some hubs crash again. The queues that had been building while the hubs were down now arrive all at once. Engineers who thought they had fixed the problem watch a second wave of failures appear — caused not by the original bug, but by the recovery itself.
If you’ve spent a decade in the trenches of distributed systems, you’ve seen this play out. In the AWS us-east-1 incident on October 19, the ‘cabs’ were DynamoDB records, and the ‘scheduler’ was a broken DNS Enactor.
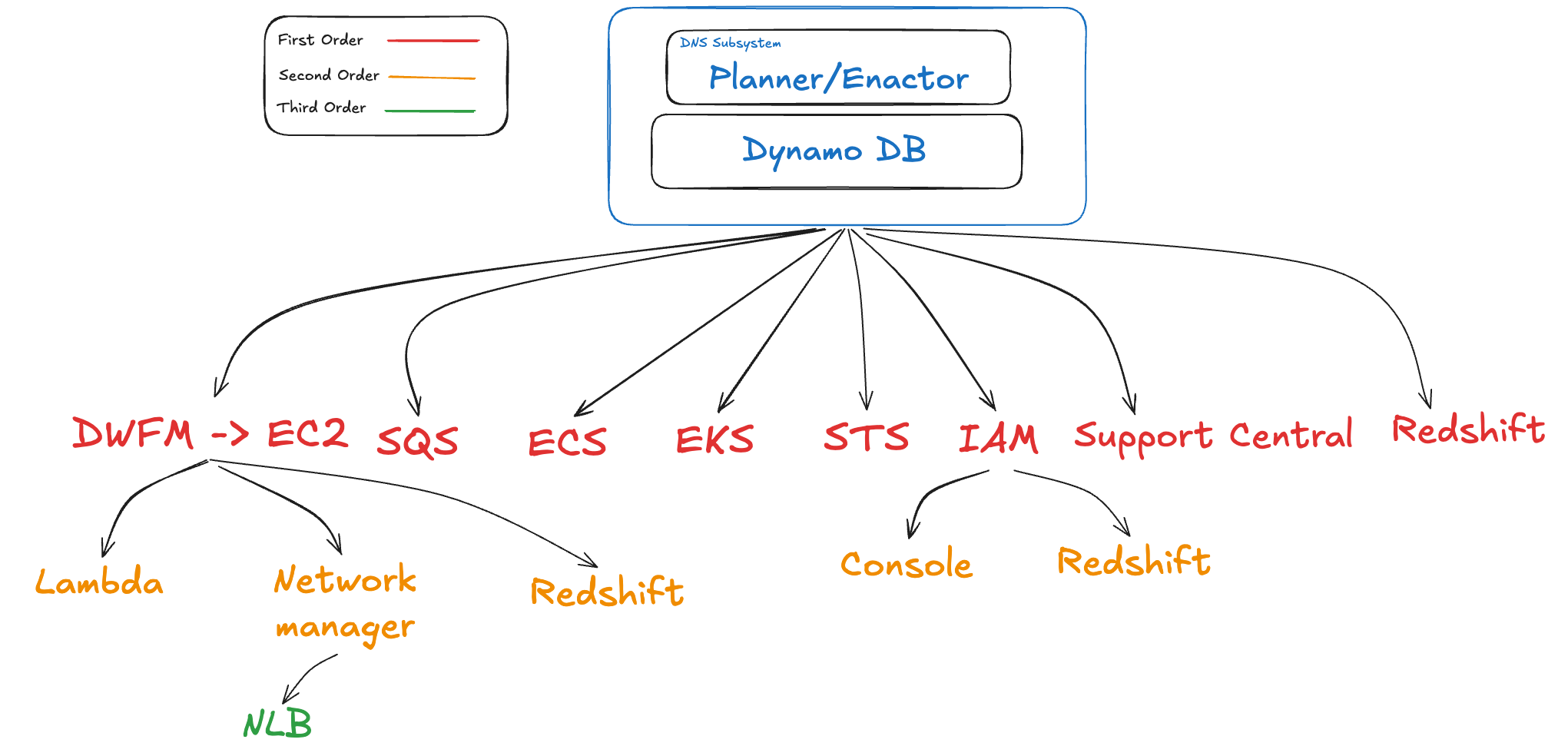
The Root Cause: A Race Condition in DNS Convergence
On the night of October 19, 2025, no server crashed. No disk failed. No network cable was unplugged. A single DNS record for dynamodb.us-east-1.amazonaws.com was quietly overwritten with nothing — an empty list of IP addresses — and stayed that way.
To understand how, you need to know how DynamoDB manages its own DNS.
DynamoDB operates at a scale most engineers never encounter. Hundreds of thousands of DNS records, constantly updated, routing traffic across a large heterogeneous fleet of load balancers. Doing this by hand is impossible. So AWS built automation — a two-component system split deliberately across two independent pieces for resilience.
The first component, the DNS Planner, watches the health and capacity of load balancers and produces a fresh DNS plan — a list of which load balancers should serve traffic, and at what weight. The second component, the DNS Enactor, takes those plans and applies them to Route 53. For resilience, three independent Enactor instances run simultaneously across three Availability Zones, each capable of applying plans on its own.
This design made sense. Decoupling the planning from the execution meant either component could fail independently without taking the other down. An Enactor that blindly trusted the Planner with no independent verification would have no safety valve. The independence was intentional — it was the last line of defense against a corrupted or stale plan.
What no one had fully mapped was what happens when two Enactors develop divergent views of the world.
Here is the exact sequence that triggered the outage. One Enactor — call it Enactor A — was running unusually slow, retrying updates on several endpoints due to high delays. While it was crawling through its work, the Planner kept running and produced many newer plan generations. A second Enactor — Enactor B — picked up one of those newer plans and applied it rapidly across all endpoints. Enactor B then ran its cleanup process, deleting plans it considered obsolete — plans many generations older than the one it had just applied.
At precisely that moment, Enactor A — still working through its stale, much older plan — successfully applied that old plan to the regional DynamoDB endpoint, overwriting Enactor B’s newer plan. The safety check that should have caught this — verifying the plan was newer than what was previously applied — was itself stale, because of the unusually high delays Enactor A had been experiencing.
Enactor B’s cleanup process then deleted Enactor A’s old plan, because it was many generations behind. As it was deleted, every IP address for the regional DynamoDB endpoint was removed from DNS. Not degraded. Not reduced. Emptied.
The system was now in an inconsistent state that no automated process could repair. It required a human to fix.
This is the check-then-act problem — one of the oldest failure modes in distributed systems. You check a condition, then act on it. But between the check and the act, the world changes. Without an atomic operation that makes the check and the act a single indivisible step, you are always trusting a snapshot of reality that may already be wrong.
The deeper irony: the independence that made this system resilient under normal conditions — two Enactors operating autonomously — is exactly what made this race condition possible. When two systems can each write to the same shared state without coordination, divergence isn’t a risk. It’s a guarantee, given enough time.
At 11:48 PM PDT, every client that needed to connect to DynamoDB in us-east-1 — customers, and internal AWS services alike — began receiving DNS failures. The blast radius clock had started.
The Cascade: When Invisible Dependencies Snap
At 11:48 PM, the DynamoDB regional endpoint went dark. What followed was not a single failure — it was a tree of failures, each branch growing from the one before it.
Most engineers think of a service outage as a vertical problem. One service goes down, its users are affected, you fix it, done. What this incident revealed is that modern cloud infrastructure fails horizontally — across services that appear unrelated, through dependencies that are invisible until they snap.
The first wave was immediate and obvious. Every AWS service that directly called DynamoDB in us-east-1 began failing within minutes. SQS event processing stopped. ECS and EKS container launches failed. STS authentication errors spiked. IAM users couldn’t log into the AWS Console. Redshift clusters couldn’t read or write data. Support Center locked out legitimate users. Each of these services had their own engineering teams, their own monitoring, their own runbooks — and none of it mattered, because the dependency they shared was invisible to all of them.
But the more consequential failure was quieter, and slower.
EC2’s DropletWorkflow Manager — DWFM — is responsible for managing the physical servers that host EC2 instances. It maintains a lease with every server under its management, checking in every few minutes to track state. This lease mechanism depended on DynamoDB. Not as a primary database. Not as a cache. As a distributed lock manager — the source of truth for which physical server was in which state.
This was a reasonable design decision. Building a custom distributed lock manager at EC2’s scale — potentially millions of servers — introduces unbounded failure modes. DynamoDB’s failure modes are known, documented, and battle-tested. Predictable failure beats unpredictable failure. The decision made sense.
What it created, however, was an invisible load-bearing wall between EC2 and DynamoDB. When DynamoDB went dark, DWFM’s state checks began failing silently. No existing EC2 instance was affected — they kept running. But every droplet slowly lost its active lease. And a droplet without an active lease is not a candidate for new EC2 instance launches.
By the time DynamoDB recovered at 2:25 AM, the EC2 fleet across the entire us-east-1 region had effectively been frozen. No new launches. No capacity.
Then the recovery made things worse.
DWFM began re-establishing leases with every droplet simultaneously. Thousands of lease requests flooded the system at once — a thundering herd. DWFM’s queue grew faster than it could process. Lease attempts timed out and re-queued. The system entered congestive collapse — unable to make forward progress, not because it was broken, but because it was overwhelmed by legitimate work arriving faster than it could be handled. There was no established recovery procedure for this scenario. Engineers had to throttle incoming work and selectively restart DWFM hosts to drain the queues manually.
By 5:28 AM DWFM had recovered. But the thundering herd wasn’t finished.
Every EC2 instance that launched after DWFM recovered needed its network configuration propagated by Network Manager — the system responsible for VPC connectivity, routing, and internet access for new instances. The backlog of network state propagations that had accumulated during the outage now arrived at Network Manager all at once. A second thundering herd. Network Manager’s latencies spiked. Newly launched EC2 instances came up without network connectivity.
This is when NLB began to fail — not during the DynamoDB outage, but after it had been fixed. NLB’s health checking subsystem brought new EC2 instances into service before their network state had fully propagated. Health checks failed on healthy instances. NLB began removing nodes from DNS, then returning them when the next health check passed, then removing them again. The oscillation increased load on the health check subsystem itself, causing it to degrade further. For multi-AZ load balancers, entire AZs were being taken out of service.
The two distinct failure periods manifested a slew of PagerDuty alerts while EC2 dashboards stayed green.
Why ‘Fixed’ Doesn’t Mean ‘Recovered’
There is an assumption embedded in how most engineers think about outages. It goes unspoken because it seems too obvious to say out loud: fix the root cause, and the system recovers.
The AWS October 2025 incident is a precise, documented counterexample to that assumption.
DynamoDB’s DNS was restored at 2:25 AM. By every conventional measure, the incident was over. The root cause had been identified, the race condition neutralized, the empty DNS record repopulated.
What happened next took until 1:50 PM the following day to fully resolve.
The problem was not that the fix was incomplete. The problem was that the recovery itself had never been designed for.
Consider what the system looked like at 2:25 AM. Across the entire us-east-1 region, every DWFM host had been unable to complete state checks for nearly three hours. Every droplet lease had expired. Every physical server that EC2 runs on was sitting in an unlicensed state, invisible to the launch system, unavailable for new instances. Thousands of customers and internal services were queued, waiting, retrying.
The moment DynamoDB came back, all of that queued demand was released simultaneously.
The first wave hit DWFM. Thousands of droplets simultaneously attempting to re-establish leases overwhelmed the system’s ability to process them. Lease attempts timed out before completing and re-queued. The queue grew faster than it drained. DWFM entered congestive collapse — a state borrowed from TCP networking, where a system becomes so overwhelmed by retries that it loses the ability to make forward progress entirely. It wasn’t broken. It was suffocating under legitimate work arriving faster than it could be handled.
There was no runbook for this scenario. Engineers attempted multiple mitigation steps carefully — this is the call nobody wants to make at 2 AM. Eventually they throttled incoming work and restarted DWFM hosts selectively to drain the queues. It worked, but it took until 5:28 AM — three hours after DynamoDB had already recovered.
The second wave hit Network Manager thirty minutes later.
Every EC2 instance launched after DWFM recovered needed its network configuration propagated before it could communicate. Three hours of backlog arrived at Network Manager simultaneously. Newly launched instances came online without network connectivity. NLB health checks began failing on instances that were structurally healthy but network-blind. The health check subsystem started oscillating — failing, recovering, failing — which increased its own load, causing it to degrade further. Engineers disabled automatic AZ failover at 9:36 AM to stop the oscillation from pulling more capacity offline.
Two thundering herds. Both triggered by recovery. Neither caused by the original bug.
The lesson here is not a criticism of how AWS responded. Rather, it’s architectural and worth carrying forward.
Recovery is a load event. This is something I have experienced even in the days of physical public facing servers running cPanel based web server. The system that just healed now receives a demand spike potentially larger than anything it was designed to handle under normal operations.
This is worth asking explicitly for any critical system you operate at scale: is there a runbook specifically for the recovery phase, not just the failure phase?
The Redshift Case: Three Paths to a Single Failure
Everything discussed so far follows a single chain. DNS fails, DynamoDB goes dark, DWFM loses its leases, EC2 can’t launch, Network Manager backlogs, NLB oscillates. One root cause, one direction of travel.
Redshift breaks that model entirely.
Redshift was not hit by this incident once. It was hit three times, through three independent failure paths, each operating on a different timeline, each requiring a different recovery action. Understanding why reveals something the dependency map alone cannot show — that blast radius is not just about how many services fail, but about how many independent routes a single failure can travel to reach the same destination.
Path One: The Direct Hit
Redshift uses DynamoDB endpoints to read and write cluster data. This is the obvious dependency — the kind that shows up in architecture diagrams and service inventories. When DynamoDB went dark at 11:48 PM, Redshift query processing stopped within minutes. This path was expected, detectable, and recoverable. When DynamoDB’s DNS was restored at 2:25 AM, Redshift query operations resumed. Clean failure, clean recovery.
If this had been the only path, Redshift would be a footnote in this incident.
Path Two: The Long Tail
Redshift clusters run on EC2 instances. When credentials expire on cluster nodes — a routine, expected event — Redshift’s automation triggers workflows to replace the underlying EC2 hosts with fresh instances. Under normal conditions this is invisible. Nodes rotate, clusters stay healthy, nobody notices.
On the night of October 19, credentials began expiring on cluster nodes while EC2 launches were impaired. The replacement workflows triggered as designed — and immediately blocked, because there were no EC2 instances to replace them with. Clusters entered a “modifying” state. In that state they were unavailable for queries.
DynamoDB recovered at 2:25 AM. EC2 recovered through the morning. But the Redshift replacement workflows had been building a backlog for hours. Engineers had to manually stop the backlog from growing at 6:45 AM. The replacement instances only started launching at 2:46 PM. The last impaired cluster was restored at 4:05 AM on October 21.
More than 28 hours after a 20-minute DNS corruption.
This path was invisible because it required two things to be true simultaneously — DynamoDB dark long enough for credentials to expire, and EC2 impaired long enough to block the replacement workflow. Neither condition alone would have caused it. The combination created a failure mode that likely existed in no runbook and appeared in no architecture review.
Path Three: The Blast Radius Escapes the Region
Redshift had a defect. When resolving user groups for IAM authentication, it called an IAM API endpoint hardcoded to us-east-1 — regardless of which region the Redshift cluster was actually running in. Under normal conditions this defect was invisible. The us-east-1 IAM endpoint was always available, always fast, never a concern.
On the night of October 19, IAM in us-east-1 was impaired. Every Redshift cluster in every AWS region that used IAM user credentials to execute queries began failing — not because their region was affected, but because they all shared a silent dependency on a single regional endpoint thousands of miles away.
A regional incident became a global one. Not through cascading load or retry storms. Simply because one hardcoded API call pointed at one region, and that region happened to be down.
What Redshift Actually Teaches
Redshift resists the instinct to find one lesson and move on. It offers three, one per path.
Path One: document your direct dependencies and test their failure modes. Table stakes.
Path Two: some failure modes only emerge when two independent conditions are true simultaneously. They live below the threshold of normal testing.
Path Three: regional isolation is only as strong as your least visible cross-region dependency.
Each path was survivable independently. The combination made recovery prolonged, parallel, and difficult to reason about in real time.
The lesson isn’t just about Redshift. Dependency mapping is an ongoing operational practice, not a one-time architecture exercise. And it needs to reach beyond what your service calls directly — into what those services assume silently, and where those assumptions point.
The Question That Remains
One race condition. A 20-minute DNS corruption that took 28 hours to fully recover from across every affected service.
The postmortem is thorough — AWS identified the race condition, published a detailed account, and the remediation list is concrete: velocity controls, scale testing, queue-depth throttling, atomic plan application. These are the right fixes. But one question remains unanswered, and it is worth sitting with. The DNS Planner and DNS Enactor were deliberately decoupled — two independent systems, each operating autonomously, each acting as a check on the other. That independence was the design. It was also the failure mode. When two systems can each write to shared state without coordination, they will eventually develop divergent views of the world. Not as a risk. As a mathematical certainty, given enough time and enough edge cases.
The question the postmortem doesn’t answer: when the Planner and the Enactor disagree, who is the source of truth?
Every distributed system that splits responsibility between two independent components faces this same tension. Decoupling buys resilience at the cost of coordination. When the two halves develop divergent views, the system needs a defined answer for that moment — not a race condition that resolves by whichever component writes last.
The second pattern is less visible but equally consequential. When a critical dependency comes back after hours of darkness, every waiting client reconnects at once, every blocked queue drains simultaneously, every retry fires together. This incident had two of those spikes back to back, each generating its own cascade. The engineers who responded had no runbook for either. They figured it out — but figuring it out cost hours.
The race condition has been fixed. The empty DNS record won’t happen again in this specific way. But the patterns it exposed — hidden dependencies, multi-path blast radius, recovery as a failure domain, decoupled systems with no defined source of truth — are not unique to AWS. They are properties of distributed systems at scale.
Worth knowing where yours are.