S3 Files and the Coordination Tax in Regulated Data Pipelines
By Manu Balakrishnan Sreekumari
Amazon S3 Files launched on April 7, 2026. It is the first native file system interface for S3. It exposes S3 buckets as fully POSIX-compliant filesystems over NFS v4.1, with read-after-write consistency, advisory file locking, and owner/group/mode permissions stored as S3 object metadata. You can mount it from EC2, ECS, EKS, AWS Fargate, and Lambda. Your application sees a standard mount point. It gives you flexible and transparent access to object storage.
Under the hood, S3 Files is built on Amazon EFS, delivering sub-millisecond latency for active data from a high-performance hot tier, and serving large sequential reads directly from S3 to maximise throughput. Changes written to the filesystem sync back to S3 within 60 seconds. Changes made directly to S3 objects appear in the filesystem within seconds.
Before I explain why this matters for regulated data pipelines, let me borrow an analogy from a summer cookout.
Imagine you are cooking a large meal for family and friends. You have done this before. You know the drill — everything gets bought in bulk and stored in the basement freezer, and every time someone needs an ingredient, they make the trip downstairs, bring it up, use what they need, and figure out what to do with the rest. It works. The food is durable, nothing spoils.
The problem is the trips. Every cook needs their own portion. Someone brings up too much and leaves the surplus on the counter. Someone else brings up a different batch of the same ingredient and now there are two versions in two places and nobody is sure which one is fresher. The coordination overhead of getting the right ingredient to the right cook at the right time has quietly become its own job.
S3 Files is the cooler you bring upstairs. Sized to your workload. Stocked from the freezer automatically. Every cook reaches into the same cooler. The freezer — S3 — remains the source of truth. The trips become manageable and less frequent now.
The Legacy of Friction: The Cost of Discrete Pipelines
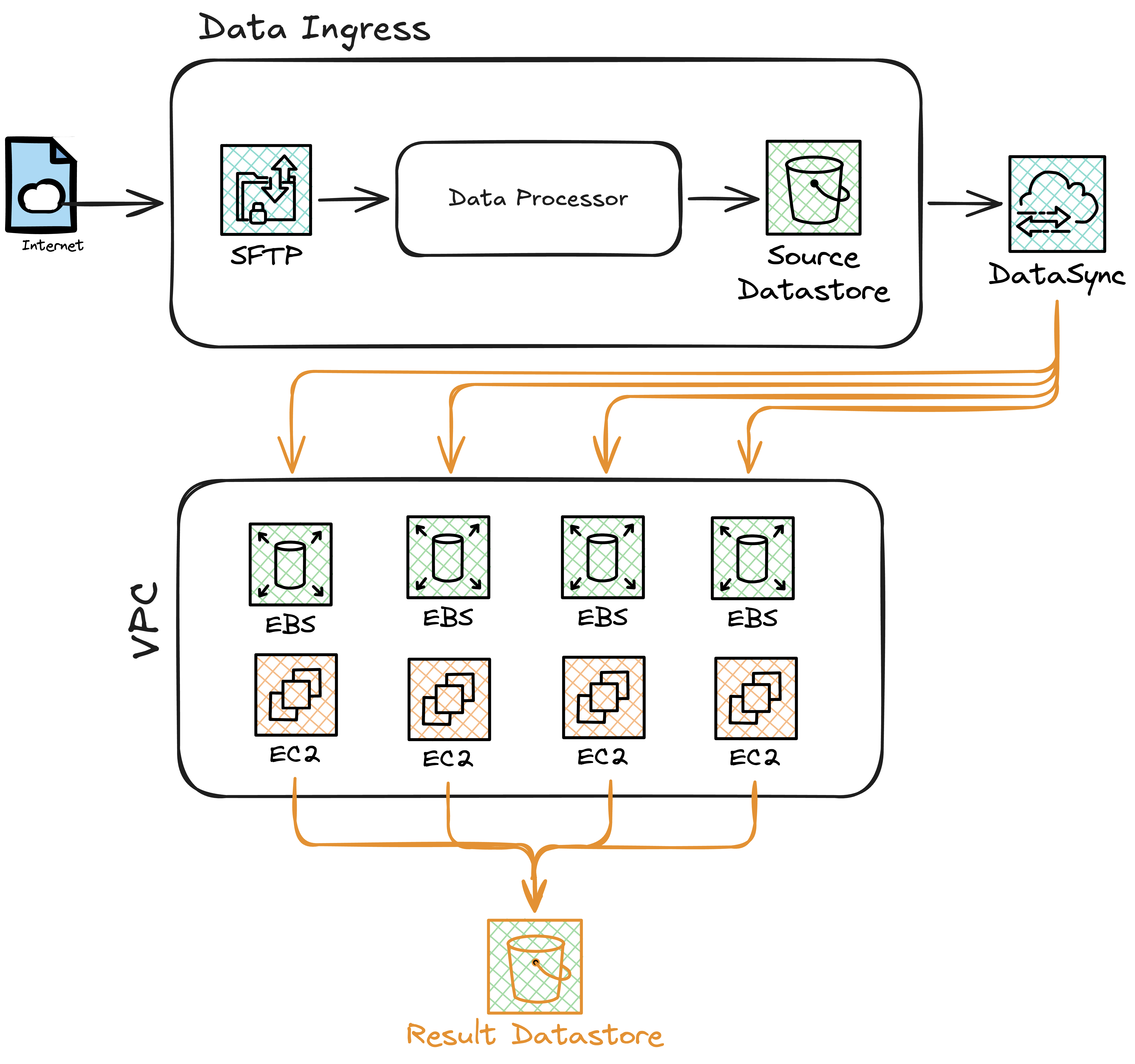
I’ve designed and operated data ingress pipelines over the years. In regulated healthcare and automotive — two industries where the data sender is a third party, the data is regulated, and the question “which copy is the authoritative one?” is never rhetorical — the architecture tends to converge on the same shape.
Lets assume a pipeline where data arrives over SFTP. It goes through a malware scanner. It lands in a Source bucket in governance mode, versioned, with strict read-only access granted to exactly one service role — the one that moves it downstream. Nothing else writes to that bucket. That permission boundary is enforced by design.
From there, DataSync fans the data out to the compute layer. In our case that meant multiple EC2 instances, each with its own EBS volume, each receiving its own copy of the dataset. The data engineer runs a cross-check against the metadata list provided by the sender to confirm every expected file arrived. Processing runs. Results land in a Result bucket.
It works. It is auditable. Every data movement is a discrete, loggable event — SFTP receipt, malware scan, Source bucket write, DataSync transfer, Result bucket write. When an auditor asks when a specific file moved and who touched it, you have an answer at every boundary.
What it costs is a different question.
The DataSync job was an asynchronous operation we had to manage, monitor, and retry. Given the coordination overhead, the team ended up with AWS WorkSpaces instances mapped per account — a manual step that also produced data processing and cleanup cycles that could have been avoided entirely if we had dynamic compute that spun up per job. The EBS volumes meant independent copies of the same dataset sitting on different instances. When a processing job on one instance produced a result, that result had to be written to the Result S3 bucket — another explicit data movement step. Every boundary that made the system auditable also made it a place where something could go wrong.
This is not a bad architecture. I want to be clear about that before going further. The explicit pipeline was the right design given the constraints: third-party data senders with their own metadata schemas, governance mode requirements, and compliance posture. The separation between the object store and the compute layer was a trade-off between durability, auditability, access control and coordination complexity.
The question S3 Files asks is a simple one: what if the storage layer could absorb that coordination complexity of data transit between Source and Result S3 bucket? How would that impact your design? And what could you stop paying the tax on?
Architectural Convergence: Bringing Compute to the Data Layer
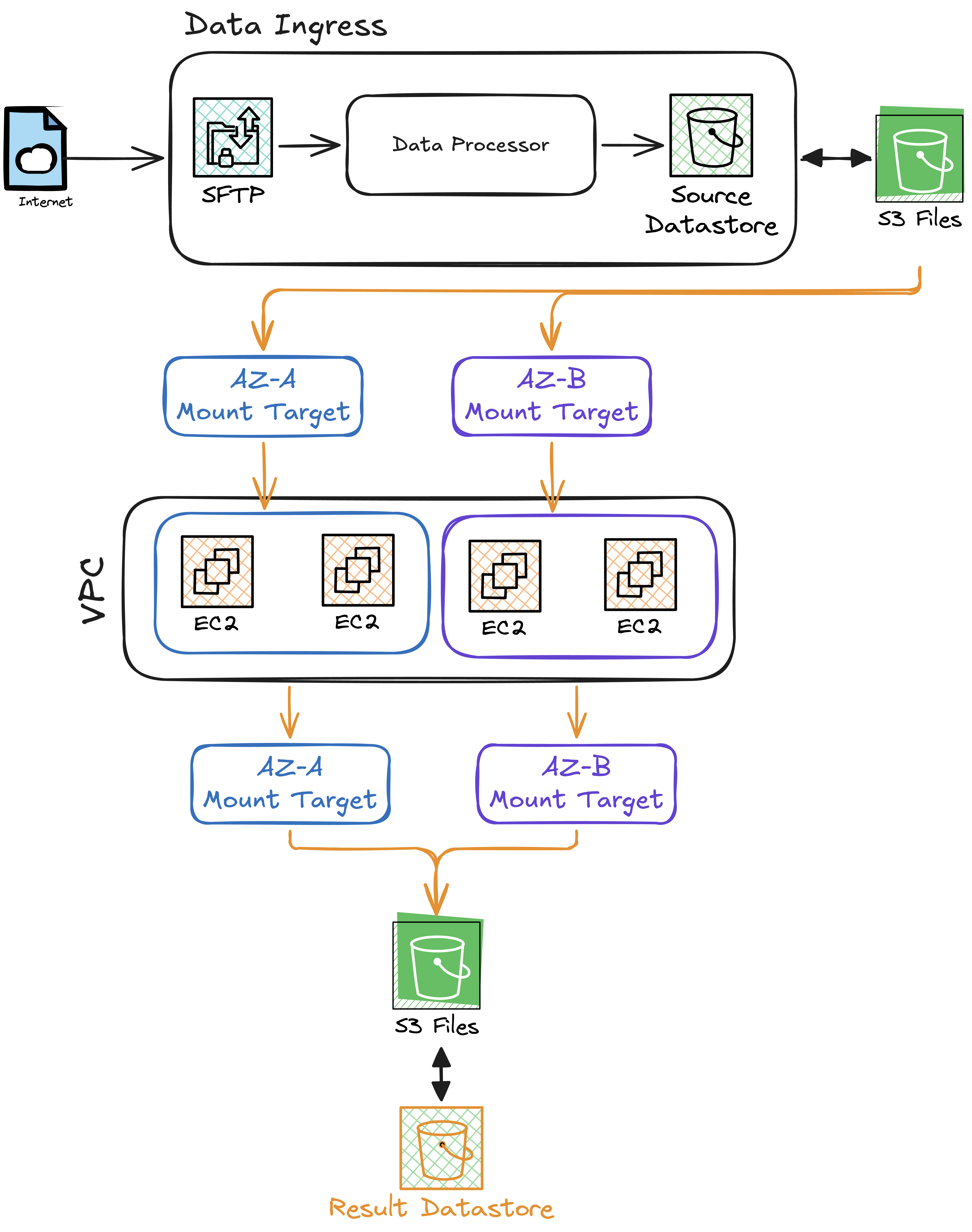
The architecture shift S3 Files enables is easier to draw than to describe, which is why I’ll start with the diagram.
In the post-S3 Files world, the DataSync job is gone. The EBS volumes are gone. The independent dataset copies are gone. What remains is a single S3 bucket — or in our case, two buckets with a clear separation of concerns — mounted directly as filesystems to the compute layer across availability zones.
The Source bucket stays exactly as it was. The ingress path doesn’t change. AWS Transfer Family is the only entity with write authority to the Source bucket.
What changes is everything downstream of that boundary.
The EC2 instances in AZ-A and AZ-B mount the Source bucket as a read-only filesystem through their respective AZ mount targets. They mount the Result bucket as read-write through the same mechanism. Processing runs directly against the mounted filesystem — avoiding the coordination complexity. The result is written to the mounted Result filesystem and S3 Files handles the synchronisation back to the Result bucket.
The dataset is no longer copied to each instance. It is accessed in place, from one location, by all instances simultaneously. When instance one and instance three are processing different files from the same dataset, they are reading from the same source. There is no reconciliation problem because there is nothing to reconcile.
This “shared truth” model represents a concrete reduction in the number of places where your data can be in an inconsistent state.
There is one thing worth naming honestly before we go further. The DataSync job that disappeared was not only moving data — it was producing an explicit, discrete audit event every time it ran. That event is gone. S3 Files synchronisation is background and implicit. CloudTrail logs management events — creating the filesystem, creating mount targets — but does not log data events like file reads and writes. If your compliance posture requires file-level audit trails, you will need to supplement with S3 server access logging on both buckets, or application-level logging in your processing layer. You should consider this carefully depending on your audit requirements.
Observability and Instrumentation Best Practices
Here is what we designed deliberately into the S3 Files architecture to maintain a durable and reliable data operation pipeline.
Conflict resolution has a silent failure mode you need to instrument. When concurrent writes hit the same object — one from the filesystem, one directly to the S3 bucket — S3 Files treats S3 as the source of truth and moves the conflicting filesystem write to a directory called .s3files-lost+found-[filesystem-id] in the root of the filesystem. That file is not copied to S3. It disappears unless you are watching. The CloudWatch metric is LostAndFoundFiles in the AWS/S3Files namespace. Alert on any non-zero value.
Data freshness requires an application-layer signal. S3 Files synchronises filesystem writes back to the Result S3 bucket every 60 seconds — however this represents a risk if you are trying to build an SLO for a downstream aggregation job without instrumentation. The approach that works: add a freshness metadata attribute to Result objects at write time, and have downstream consumers check that attribute before processing. This resolves any ambiguity about whether the data they are reading reflects the latest filesystem state. The PendingExports CloudWatch metric tells you how many files are queued for sync — higher number indicates divergence between filesystem and Result bucket.
The audit gap is real and fillable. CloudTrail does not log S3 Files data events — file reads and writes are invisible to it. Enable S3 server access logging on both the Source and Result buckets. This gives you object-level read and write events with timestamps, requester identity, and request parameters.
Here are some additional metrics offered by S3 Files that I would recommend to improve service reliability:
| Metric | Namespace | Alert threshold |
|---|---|---|
LostAndFoundFiles |
AWS/S3Files |
Any non-zero |
ExportFailures |
AWS/S3Files |
Any non-zero |
ImportFailures |
AWS/S3Files |
Any non-zero |
PendingExports |
AWS/S3Files |
Sustained non-zero over 10 min |
NFSConnectionAccessible |
efs-utils/S3Files |
Value = 0 |
S3BucketAccessible |
efs-utils/S3Files |
Value = 0 |
The Coordinator You Didn’t Know You Were Building
Every data pipeline I’ve operated in a regulated environment had a coordination layer that emerged from the gap between object storage and compute. DataSync jobs, EBS copies, WorkSpaces per account, cross-check scripts against sender metadata. None of that was the point. The point was processing the data. The coordination layer was the tax.
S3 Files doesn’t eliminate the need for careful architecture in regulated environments.
But the coordination layer — the part that existed purely because object storage and compute couldn’t agree on how to talk to each other — that part is gone. The dataset doesn’t move to the compute anymore. The compute comes to the dataset.
AWS has a pattern with storage services: launch, iterate, and close gaps based on production feedback. EFS looked experimental in 2015. Today it is foundational infrastructure for workloads that would have used NAS a decade ago. S3 Files is at the beginning of that curve.
Six months from now, after real production workloads have stress-tested the sync latency, edge cases, and the compliance posture under audit, there will be more to say. But you don’t need six months of production data to start asking whether the coordination layer you built was ever really yours to own.
Guardrails for S3 Files Adoption
S3 Files earns its place when your workload has specific characteristics that object storage was never designed to serve well.
If your application depends on POSIX semantics — atomic renames, advisory file locking, owner/group/mode permissions — S3 Files gives you those guarantees where raw S3 does not. If you are running legacy or specialised tooling that expects a local mount point and has no concept of an SDK or API — FFmpeg pipelines, older CMS platforms, data processing tools written before object storage existed — S3 Files lets that software run without modification. If your workload requires in-place updates, random reads within a large file, or sub-millisecond access latency for a hot working set, the EFS hot tier underneath S3 Files is doing real work that the S3 API cannot replicate.
There are workloads where S3 Files is the wrong answer and the distinction matters. A live transactional database needs block-level storage — EBS, not a filesystem layer over object storage. Microsecond-latency messaging between microservices belongs in ElastiCache, not a shared mount. Transient scratch space for CI/CD builds is faster and cheaper on instance store or a small EFS volume than on S3 Files, where you are paying for durability and synchronisation you don’t need for data that lives for minutes.
S3 Files sits in a specific and well-defined position in the AWS storage landscape. It is a purpose-built solution for shared, durable, POSIX-accessible data that multiple compute resources need to collaborate on.
If you want to see the Terraform implementation and a Lambda-focused perspective on the same feature, Darryl Ruggles has covered that comprehensively at darryl-ruggles.cloud.
A follow-up to this article will cover S3 Files in production — real sync latency data, lost and found edge cases under load, and what a compliance audit looks like when your pipeline lives in the storage layer.