The Role Drift Problem Nobody Talks About
A new AWS account is provisioned. A runner role is created from a template. Everything is clean.

Then a team needs S3 access to a specific bucket. Support adds a statement. Another team needs ECR pull permissions. Another statement. Six months later that role is a 47-statement Frankenstein nobody fully understands, every account is subtly different, and the only person who knows why AllowLegacyBatchJobThing exists left the company in March.
This is the runner role drift problem. Almost every org hits it, because almost every org makes the same foundational mistake.
The mental model mismatch
The mistake is not the tooling. It is not the process. It’s that we’re thinking about runner roles wrong.
We create them as monoliths — one role, one policy, one thing to manage. But in practice, a runner role is asked to carry four completely distinct responsibilities simultaneously:
- permissions every runner needs regardless of context,
- permissions specific to a team’s workload,
- permissions that vary by environment (prod vs staging vs dev),
- permissions specific to a single account’s quirks.
When you treat four things as one thing, you get chaos. Every ticket that comes in gets duct-taped onto the monolith because there’s nowhere else to put it. The role becomes load-bearing in ways nobody planned for.
The fix isn’t better ticket discipline. It’s decomposing the monolith into what it actually is.
The layer cake model
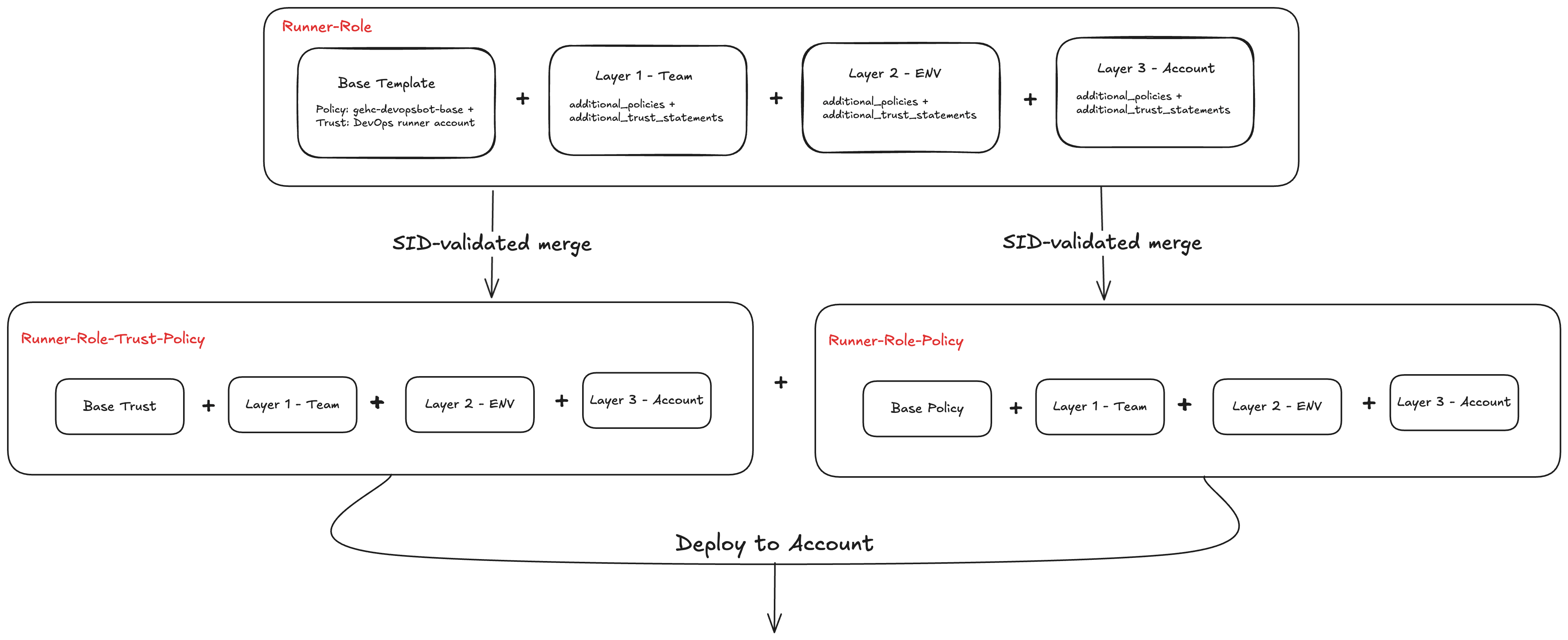
The model is simple: four layers, each with a clear owner and a clear scope.
- Global permissions are the foundation — what every runner in every account needs.
- Team permissions sit above that, expressing what a specific team’s workload requires.
- Environment permissions handle the prod/non-prod split — different S3 retention policies, different KMS keys, stricter network egress in production.
- Account permissions are the smallest layer — the legitimately one-off things that differ per account.
Each layer lives as its own policy document in version control. Not combined, not merged by hand — separate files with separate owners and separate review paths. A change to team permissions goes through the team’s review process. A change to global permissions gets broader scrutiny. The layers have different change velocities and different blast radii, so they get different governance.
At deploy time, the CICD pipeline blends them into a single effective policy document and hands it to AWS. Think of it like CSS specificity — you don’t ship one monolithic stylesheet per page. You layer browser defaults, external stylesheets, and inline styles, and the cascade resolves at render time. Same idea here. The effective permission set is the cascade result, not a hand-stitched artifact frozen in time.
Delegating the hard problem
One decision that deserves to be explicit: we don’t implement our own precedence logic.
When layers conflict, AWS resolves it. AWS’s policy evaluation logic is well-documented, battle-tested, and not our code to maintain. Our pipeline’s job is to produce a valid, non-conflicting policy document — not to second-guess the evaluator.
The one thing we do enforce is duplicate SIDs. AWS will reject a policy document with duplicate Statement IDs outright, so the pipeline catches that at merge time and fails loud before anything reaches the API. That’s the right failure mode — shift left, fail fast, make the problem visible to the person who caused it rather than to the on-call engineer three days later.
SIDs are mandatory in this model, and naming convention is enforced: GlobalS3ReadAccess, TeamDevECRPull, EnvProdKMSDecrypt. When you’re debugging an access issue six months from now and you pull the effective policy, you can read exactly which layer each statement came from. That traceability is worth the discipline it requires.
Code is a liability
There’s a principle worth stating plainly here: code is a liability, not an asset.
Every line of custom precedence logic we write is a future incident. It needs to be tested, documented, understood by whoever is on-call at 2am, and kept current as AWS’s IAM behavior evolves around it. The temptation when building tools like this is to solve every edge case in code. Resist it.
Our tool is a gatekeeper, not a governor. It validates at the boundary — are the SIDs unique, are the layers well-formed, does the merged document pass schema validation — and then it gets out of the way and trusts the platform. The minimum viable defensive layer, and nothing more.
What this unlocks
When your runner roles are composable and CICD-managed, a few things become possible that weren’t before.
- Drift detection is trivial — you know exactly what every role should look like at any point in time because it’s derived from source-controlled layers.
- Auditability is real — every permission change has a PR, a reviewer, and a timestamp.
- Onboarding new accounts becomes a composition problem, not a copy-paste problem — you select the layers that apply and deploy.
The account-specific drift goes away. Not because of better process discipline, but because the architecture makes accidental divergence structurally harder to create than doing it right.
The real problem is ownership, not tickets
This model only works if ownership is explicit.
The layering isn’t just technical — it’s an ownership model. Global permissions are a platform concern. Team permissions are a service owner concern. Environment permissions belong to whoever is accountable for prod. Account permissions are the account owner’s last mile.
If you leave that blurry, the next ticket will still become another statement in the monolith. The point of layered policies is not to make change impossible — it’s to make change obvious.
When the only person who knows why AllowLegacyBatchJobThing exists leaves the company, the policy should still tell a story. If the story is split across four layers, that story is readable.
Conclusion
Runner role entropy is a specific problem with a common cause: we build monoliths and then ask them to be everything to everyone.
The answer is not a better ticket process. It’s a better architecture.
Separate global, team, environment, and account permissions. Keep them in version control. Enforce SIDs and fail loudly on duplicates. Let AWS do the evaluation. Let your pipeline do only the validation.
Then the next time a team needs new access, the answer is not “add one more statement.” The answer is “which layer owns this change?”
In Part 2, we’ll dive into how to design the source-controlled layer structure, validate policy merges in CI/CD, and keep your runner roles readable over time.